Autocannon
Autocannon es una librería de benchmarking inspirada en wrk y escrita en Javascript, la cual nos permite probar la carga de nuestro sitio web o API.
Instalación y uso
Debemos tener instalado node en nuestro equipo. Luego basta con instalar la librería de forma global para disponer de la misma para cualquier prueba:
npm i autocannon -g
Sólo con ello ya podremos ejecutar una prueba, con un comando similar al siguiente:
autocannon -c 100 -d 5 -p 10 http://localhost:3000
En el comando anterior estamos indicando los siguientes parámetros:
- -c: cantidad de conexiones.
- -d: la cantidad de segundos que se ejecutará la prueba (duración).
- -p: la cantidad de solicitudes canalizadas (pipelined requests).
- La URL y puerto del servicio que deseamos probar
Como resultado, veremos un reporte similar al siguiente:
Running 10s test @ http://localhost:3000
100 connections with 10 pipelining factor
┌─────────┬───────┬────────┬────────┬────────┬───────────┬──────────┬────────┐
│ Stat │ 2.5% │ 50% │ 97.5% │ 99% │ Avg │ Stdev │ Max │
├─────────┼───────┼────────┼────────┼────────┼───────────┼──────────┼────────┤
│ Latency │ 91 ms │ 117 ms │ 173 ms │ 211 ms │ 122.55 ms │ 22.25 ms │ 282 ms │
└─────────┴───────┴────────┴────────┴────────┴───────────┴──────────┴────────┘
┌───────────┬─────────┬─────────┬─────────┬────────┬─────────┬─────────┬─────────┐
│ Stat │ 1% │ 2.5% │ 50% │ 97.5% │ Avg │ Stdev │ Min │
├───────────┼─────────┼─────────┼─────────┼────────┼─────────┼─────────┼─────────┤
│ Req/Sec │ 5535 │ 5535 │ 8187 │ 9543 │ 8110.2 │ 1027.76 │ 5533 │
├───────────┼─────────┼─────────┼─────────┼────────┼─────────┼─────────┼─────────┤
│ Bytes/Sec │ 1.27 MB │ 1.27 MB │ 1.88 MB │ 2.2 MB │ 1.87 MB │ 237 kB │ 1.27 MB │
└───────────┴─────────┴─────────┴─────────┴────────┴─────────┴─────────┴─────────┘
Req/Bytes counts sampled once per second.
# of samples: 10
Estos resultados se muestran en percentiles, es decir, una serie de categorías o grupos en los que “cae” cada individuo de nuestra población dada una característica del mismo. En la primera tabla, un individuo es una solicitud. En la segunda tabla en cambio, un individuo es un segundo de tiempo, y como hemos ejecutado la prueba durante 10 segundos (indicado con el argumento -d), el número de muestras es 10, valor que se indica al final de la salida de consola. Cada percentil incluye a los anteriores y se lee de la siguiente manera tomando como ejemplo la latencia en el percentil 99: el 99% de los casos, la solicitud requirió a lo sumo 211ms. Es esta forma que podemos capitalizar esta información, comprendiendo cuál es la cota superior para un porcentaje de las solicitudes que se ejecutarion (nuestra población), o dicho de otra forma, la posición de un valor en relación con el resto.
Dicho lo anterior, al observar la primera tabla del ejemplo vemos que las solicitudes más rápidas, definidas en el percentil 2.5% (0% … 2.5%), presentaron una latencia máxima de 91ms. En el otro extremo, las más lentas (99%) mostraron una latencia de hasta 211ms. Luego tenemos métricas adicionales, como la latencia promedio, la desviación estándar y la máxima.
De forma análoga, en la segunda tabla veremos la cantidad de solicitudes por segundo en la primera fila y la cantidad de bytes descargados por segundo en la segunda.
Indicando la cantidad de solicitudes
Una alternativa al parámetro duration (-d) es amount (-a), con el cual podremos indicar la cantidad de solicitudes. Si indicamos -a, -d será ignorado.
autocannon -c 100 -d 5 -a 10000 -p 10 http://localhost:3000
Running 10000 requests test @ http://localhost:3000
100 connections with 10 pipelining factor
running [================== ] 90%
┌─────────┬────────┬────────┬────────┬────────┬───────────┬──────────┬────────┐
│ Stat │ 2.5% │ 50% │ 97.5% │ 99% │ Avg │ Stdev │ Max │
├─────────┼────────┼────────┼────────┼────────┼───────────┼──────────┼────────┤
│ Latency │ 111 ms │ 136 ms │ 171 ms │ 172 ms │ 137.52 ms │ 14.93 ms │ 185 ms │
└─────────┴────────┴────────┴────────┴────────┴───────────┴──────────┴────────┘
┌───────────┬────────┬────────┬────────┬─────────┬─────────┬────────┬────────┐
│ Stat │ 1% │ 2.5% │ 50% │ 97.5% │ Avg │ Stdev │ Min │
├───────────┼────────┼────────┼────────┼─────────┼─────────┼────────┼────────┤
│ Req/Sec │ 2101 │ 2101 │ 2101 │ 7003 │ 4551.5 │ 2450.5 │ 2100 │
├───────────┼────────┼────────┼────────┼─────────┼─────────┼────────┼────────┤
│ Bytes/Sec │ 483 kB │ 483 kB │ 483 kB │ 1.61 MB │ 1.05 MB │ 564 kB │ 483 kB │
└───────────┴────────┴────────┴────────┴─────────┴─────────┴────────┴────────┘
Analizando la latencia en base a la cantidad de conexiones
Con lo aprendido hasta ahora, sería interesante correr algunas pruebas para comprender cómo se comportará nuestro sitio en función de la cantidad de conexiones concurrentes. Para esto usaremos el argumento -l, con el cual se nos mostrará toda la información de latencia. Además incrementaremos a 20 la duración y dejaremos el valor de pipelining en 1, cuyo valor es el predeterminado. Ejecutaremos además el mismo comando para 10, 100, 500 y 1000 conexiones:
autocannon -c 10 -d 20 -p 1 -l http://localhost:3000
autocannon -c 100 -d 20 -p 1 -l http://localhost:3000
autocannon -c 500 -d 20 -p 1 -l http://localhost:3000
autocannon -c 1000 -d 20 -p 1 -l http://localhost:3000
Con las tablas resultantes crearemos además un gráfico en Google Spreadsheets para tener una mejor visualización de los resultados.

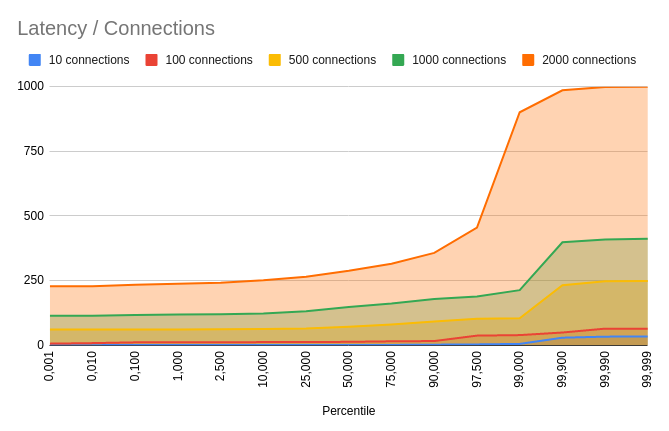
Contando con el gráfico, podemos proceder a sacar algunas conclusiones sobre este servicio:
- Se observa un crecimiento geométrico en la latencia mínima en función de la cantidad de conexiones.
- En general, El 25% de las conexiones más rápidas mantienen un tiempo de respuesta similar (+-10% de tiempo), el cual puede hasta duplicarse hasta el percentil 97,5. Para el 2,5% más lento, el tiempo de respuesta se degrada drásticamente, requiriendo aproximadamente 4 veces más tiempo para resolverse.
Automatizando el proceso
Si deseamos llevar a cabo este análisis de forma recurrente, lo más lógico sería automatizar el proceso. Para ello Autocannon cuenta con dos herramientas adicionales:
- La salida en formato JSON: para lo cual basta con agregar el argumento -j, obteniendo de esta forma una salida fácil de digerir por cualquier plataforma de análisis.
- Una API que nos permitirá llevar esta tarea de forma programática.
Concluyendo
Autocannon es una librería no sólo ligera y facil de utilizar, sino además muy útil para llevar a cabo pruebas empíricas de carga en nuestros sistemas web.